Aurora: Real-Time Analytics Platform for Kafka Streams
Introduction
Section titled “Introduction”Aurora is an open-source, integrated data platform that bridges the gap between Apache Kafka’s high-throughput event streaming capabilities and the analytical needs of data teams. Built with modern cloud-native architecture, Aurora addresses the complex challenge of making real-time data accessible and actionable for teams without deep data engineering expertise.
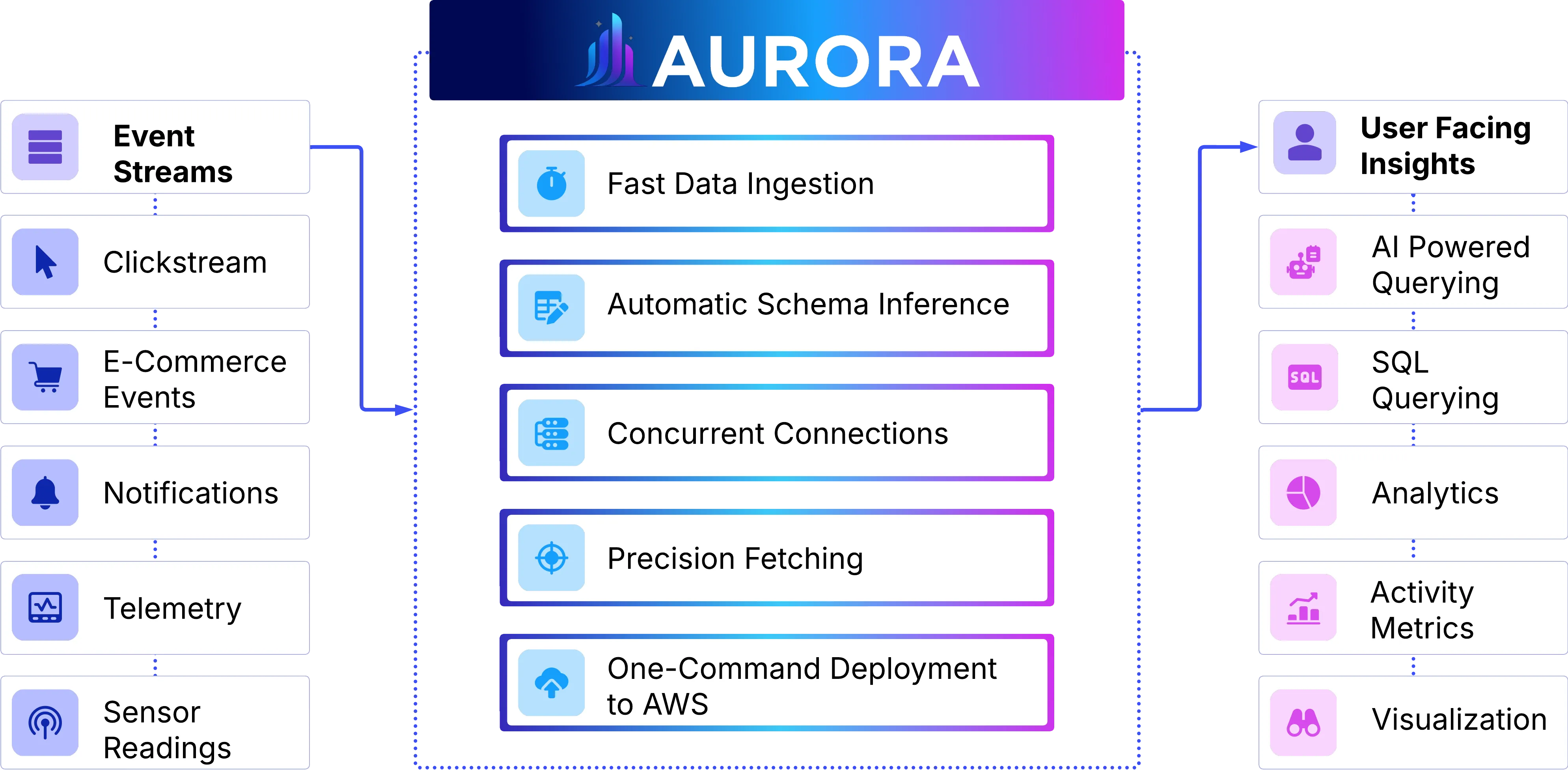
Aurora CLI automatically deploys infrastructure composed of four core components: a streaming pipeline for real-time data ingestion, a natural language query engine for converting business questions into queries, a visualization layer for interactive analytics, and a web application that delivers a unified user interface.
By provisioning these components directly into the cloud, Aurora enables real-time exploration, analysis, and visualization of event data without the complexity of custom tooling or the cost overhead of managed services. This integrated approach mitigates the conventional challenges associated with data ingestion, processing, and analysis, enabling teams to derive insights from raw data within seconds of installation.
Key Technical Achievements:
- Sub-5 second end-to-end latency from Kafka consumption to queryable data
- Scalable modular architecture, load-tested for 1,000+ events/second burst capacity with 200 events/second sustained load and 99.7% delivery reliability
- Natural language query interface powered by OpenAI with custom schema-aware context implementation, achieving 87.5% accuracy in load testing
- Integrated visualization layer with automated Grafana connection and configuration
- One-command AWS deployment with automated Terraform provisioning of 17+ infrastructure components, reducing deployment time from 4-8 hours to 5-10 minutes (95%+ time reduction)
This case study examines the real-world engineering challenges we solved, architectural decisions we made, and performance optimizations we implemented while building Aurora. It investigates how Aurora addresses these challenges through its modular architecture and the technical trade-offs involved in creating a system that balances ease of use with production-grade reliability and performance.
The Problem: Event Streams as Data Silos
Section titled “The Problem: Event Streams as Data Silos”In today’s data-driven landscape, teams increasingly rely on Kafka for real-time event streaming to handle the massive volumes of data generated by modern applications. As organizations scale their operations and require low-latency processing of continuous data flows, Kafka’s distributed architecture provides the necessary infrastructure to support high-throughput, fault-tolerant message streaming across multiple consumers and producers. This shift toward event-driven architectures reflects what Martin Kleppmann describes as the fundamental challenge of modern data systems, “the need to process data as it arrives, rather than waiting to accumulate it in batches” (Kleppmann, 2017, p. 441).
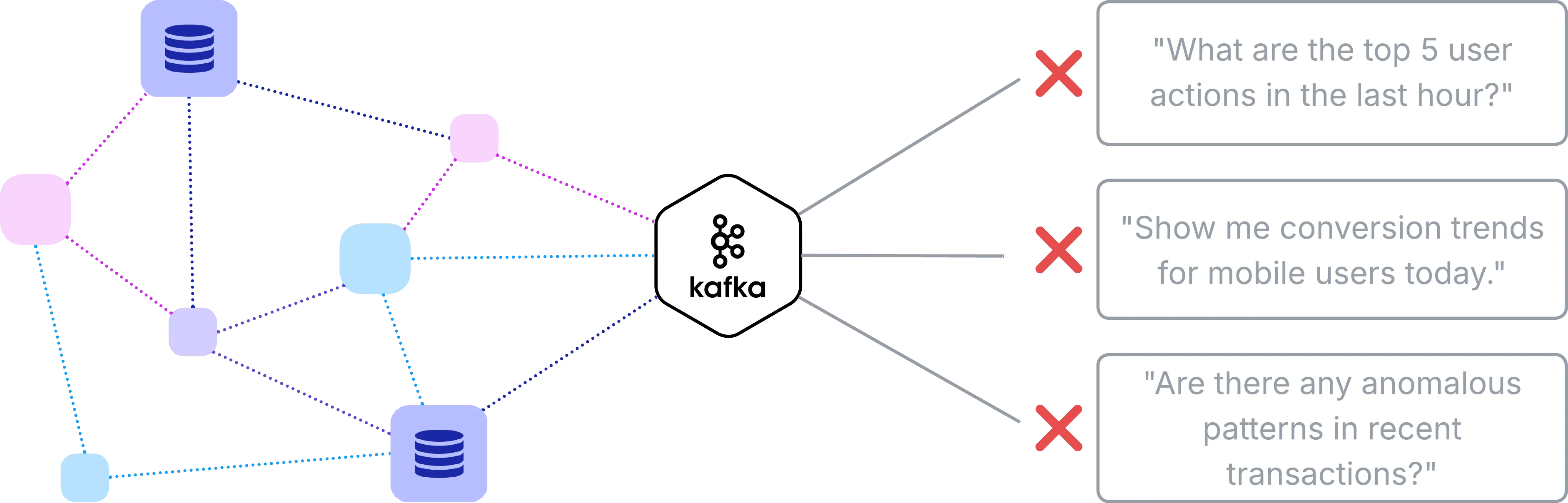
However, while Kafka excels at ingestion and distribution, it presents a significant barrier to data analysis: Kafka streams are optimized for throughput, not exploration. As Akidau et al. note in their comprehensive analysis of streaming architectures, streaming systems are fundamentally “designed with infinite datasets in mind” rather than the bounded, queryable datasets that enable flexible analytical exploration (Akidau et al., 2019, p. 4).
This creates a fundamental disconnect. Data teams need to ask questions like:
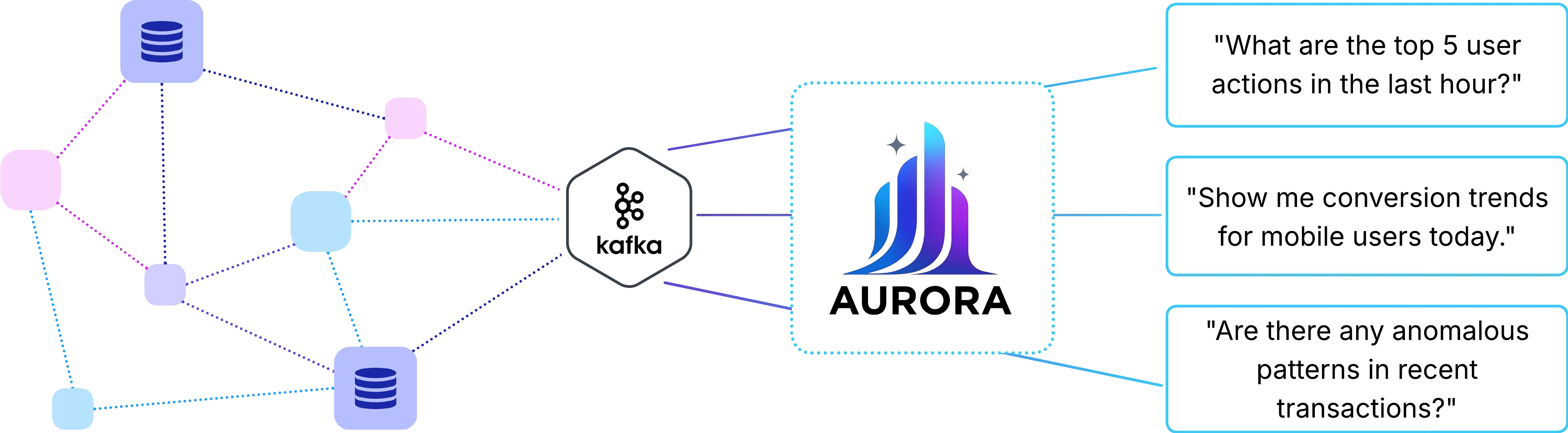
- “What are the top 5 user actions in the last hour?”
- “Show me conversion trends for mobile users today”
- “Are there any anomalous patterns in recent transactions?”
With traditional Kafka tooling, even simple questions require building custom consumers and complex streaming logic. And business users who want to ask questions in natural language (e.g., “How many orders did we get from California this week?”) are completely blocked without technical intervention.
Market Context and Positioning
Section titled “Market Context and Positioning”Consider an e-commerce platform that streams user behavior through Kafka: page views, cart additions, purchases, etc. The analytics team wants to compute real-time conversion rates and build dashboards for stakeholders, while business users want to ask ad-hoc questions about customer behavior without writing SQL.
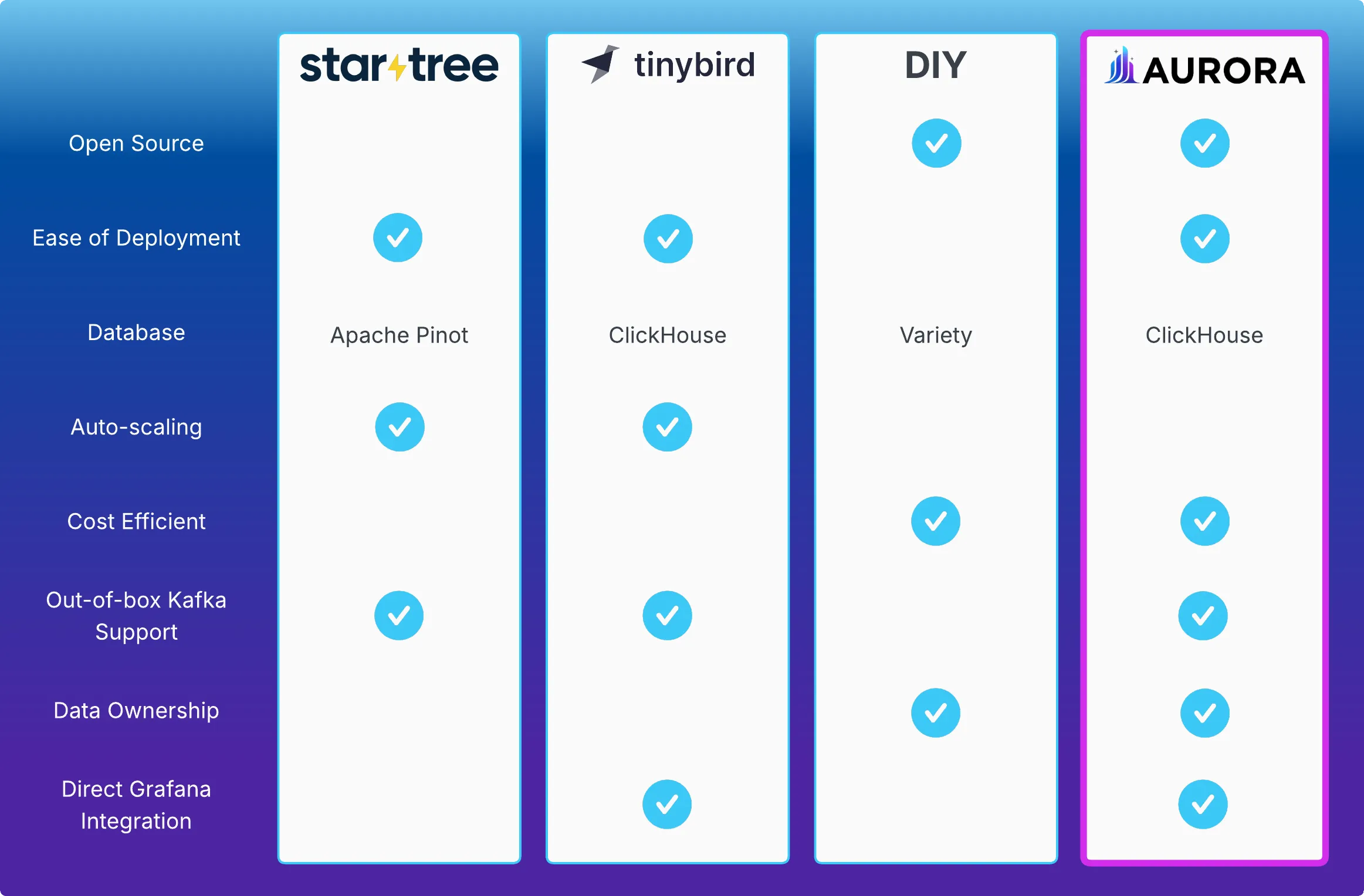
Companies facing these demands often encounter a tough choice between managed services for Kafka analytics or building a custom infrastructure, each with its own set of trade-offs:
- Managed Services (Tinybird, StarTree): Offer powerful features but introduce vendor dependencies and recurring costs.
- DIY Solutions: Provide maximum flexibility but require significant engineering resources for infrastructure management, monitoring, and scaling.
- Aurora, on the other hand, aims to combine the ease of managed services with the control of self-hosted solutions. It automatically provisions and manages the necessary infrastructure while keeping everything within your AWS environment, with both technical and non-technical users able to extract insights through natural language, SQL, or visual dashboards.
Key Differentiators
Section titled “Key Differentiators”- Zero vendor lock-in: All infrastructure runs in your AWS account
- Multi-interface access: Natural language queries, SQL queries, and Grafana dashboards
- ClickHouse performance: Columnar storage optimized for high-performance analytics with high ingestion rates (Schulze et al., 2024, p. 3731)
- Grafana Integration: Built-in Grafana instance, configured and connected
- Automated deployment: Single command deploys the entire stack
- Cost efficiency: Expenses limited to AWS hosting and OpenAI tokens
- Open source: Full transparency and customization capability
Technical Challenges
Section titled “Technical Challenges”Building Aurora required solving several core engineering problems. The first major challenge was high-performance data ingestion, which involved streaming events while maintaining ordering guarantees, handling schema evolution, and optimizing for efficient columnar storage. The second key area was natural language query processing, where advanced language models are combined with dynamic schema context to translate business questions into efficient database queries. The third challenge was supporting real-time visualization, achieved by automatically provisioning a suitable BI tool with appropriate data source configurations.
Then we needed to bring everything together in an intuitive web app that allowed users to manage connections, run queries, and access visualizations seamlessly. Finally, infrastructure automation played a crucial role, enabling the deployment and configuration of a distributed system stack without any manual intervention.
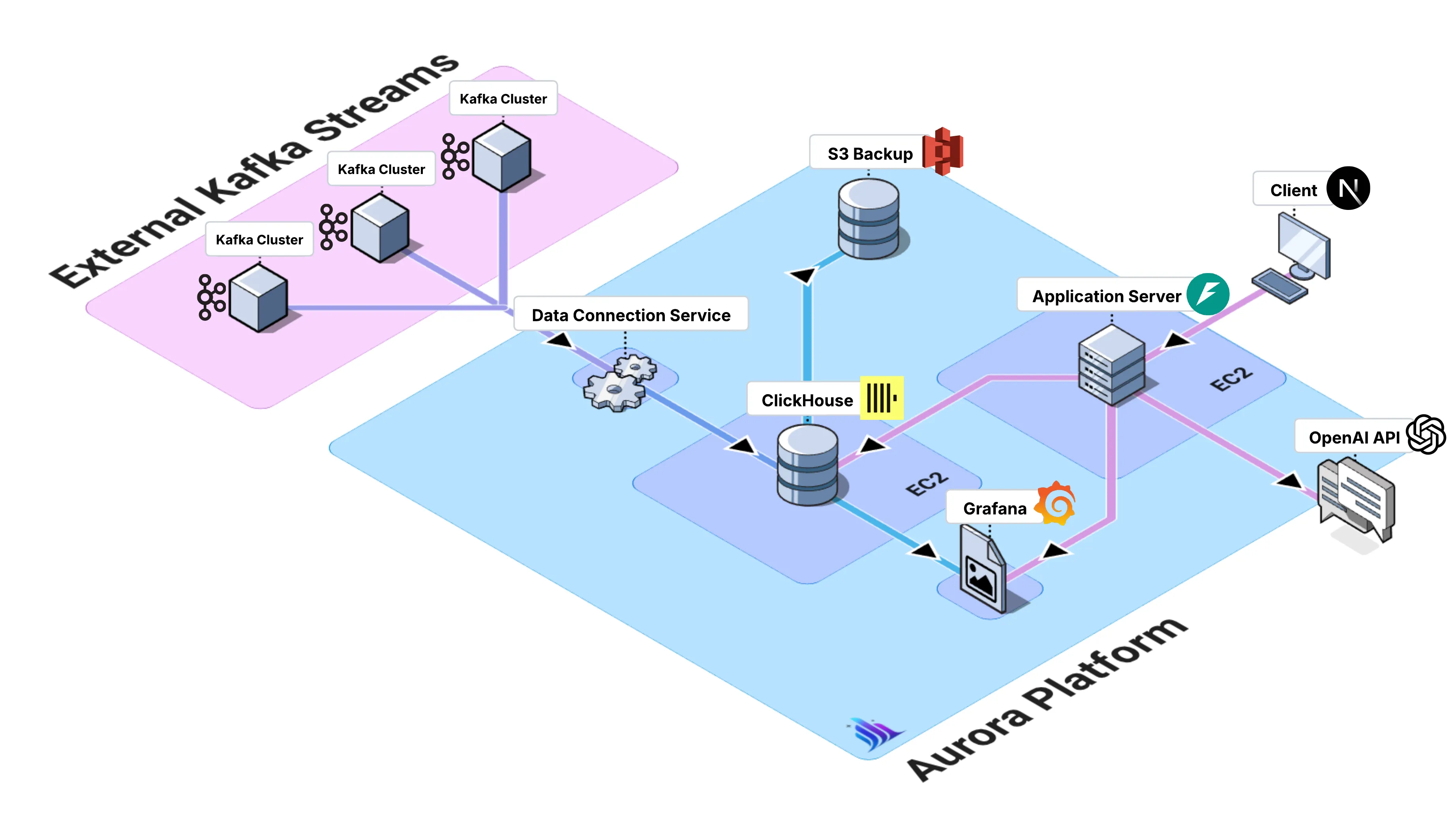
Aurora Architecture Overview
Section titled “Aurora Architecture Overview”Our answer to these challenges consists of five core components we engineered:
Aurora Web App: A mobile-first web application built with TypeScript, Next.js, and Tailwind, featuring a custom three-page layout — Connect, Query, and Visualize — that highlights the platform’s core functionality.
Aurora Kafka-to-ClickHouse Connector: High-performance consumer that ingests from existing Kafka topics into ClickHouse with batch processing, automatic schema inference, and support for multiple concurrent connections.
Aurora Natural Language Query Engine: Dual-interface system supporting both direct SQL queries against ClickHouse and natural language queries that leverage OpenAI models with schema-aware context to generate optimized ClickHouse queries.
Aurora Visualization Layer: Streamlined Grafana deployment, fully automated and pre-configured with ClickHouse data sources to enable rapid setup and real-time visualization.
Aurora CLI: An infrastructure-as-code tool that automatically provisions the full Aurora AWS stack via Terraform, with zero manual steps and seamless environment-specific configuration.
What’s Next
Section titled “What’s Next”The following sections of our case study detail Aurora’s internal components, the specific engineering challenges we encountered, performance optimizations we implemented, and lessons learned during development.