Background: The Real-Time Data Challenge
The Growing Need for Real-Time Analytics
Section titled “The Growing Need for Real-Time Analytics”Modern enterprises generate and consume data at unprecedented velocity. In this environment, the ability to process and act on information as events unfold has become a core driver of competitiveness (Kleppmann, 2017, p. 533). Real-time analytics enables organizations to capture customer interactions, monitor operational performance, and detect market shifts with minimal latency, turning raw streams into actionable insight.
This demand represents a major departure from the batch-oriented paradigms that have shaped traditional data architectures. Data warehouses that rely on periodic aggregation and delayed reporting cannot keep pace with use cases where milliseconds matter: fraud detection, personalized recommendations, dynamic pricing, and predictive maintenance (Akidau et al., 2018, p. 45). As a result, engineering teams face a central challenge: designing scalable and resilient infrastructures that can sustain continuous, low-latency analytics in production environments.
Modern applications require immediate insights to optimize experiences and understand user behavior as it happens, operational intelligence to monitor system performance and business metrics in real time (Kreps, 2014, p. 12), and interactive analytics that allow users to dynamically explore data rather than relying solely on pre-built reports.
The Real-Time Data Stack Complexity
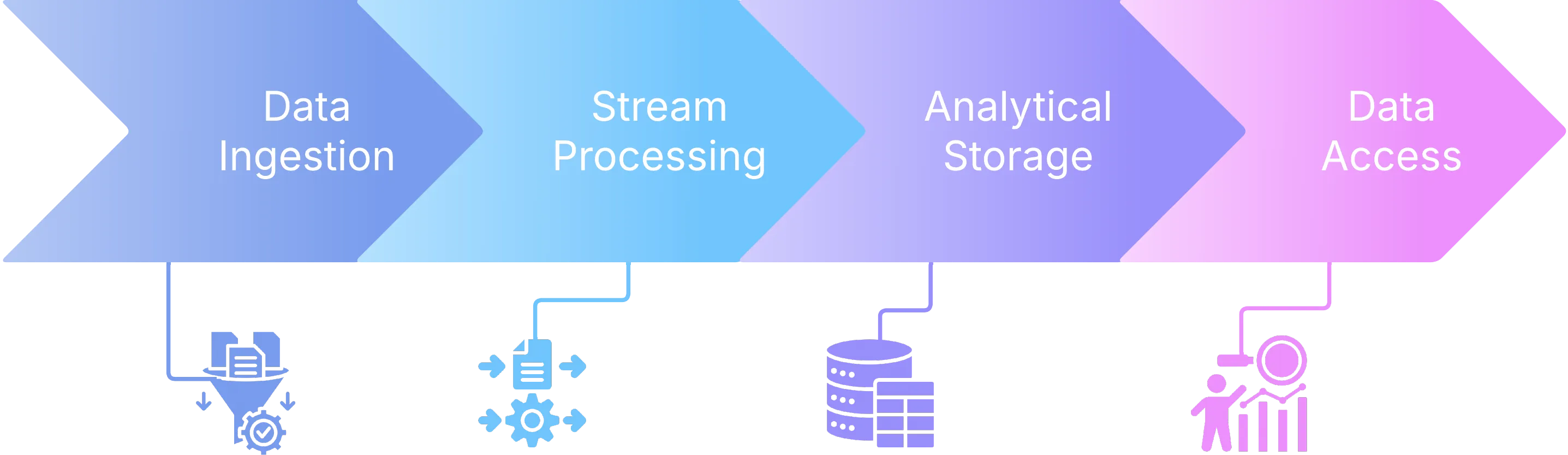
Section titled “The Real-Time Data Stack Complexity”Building a real-time data platform involves several complex components that must work together seamlessly.
Data ingestion requires systems capable of handling high-volume, high-velocity data streams through event streaming (Kreps et al., 2011, p. 2). Teams must establish well-defined schemas suitable for processing and storage, ensure data quality through validation and consistency checks, and design for scalability to handle varying load patterns without data loss.
Stream processing enables real-time transformation and enrichment of data while maintaining state management across multiple events (Akidau et al., 2018, p. 78). Error handling becomes critical to manage failures and data inconsistencies gracefully, while performance optimization ensures low-latency processing.
Analytical storage demands specialized systems optimized for real-time queries. Column-oriented storage enables faster computation over large datasets (Akidau et al., 2018, p. 156), compression techniques allow efficient storage of vast amounts of data, indexing facilitates rapid retrieval of specific data subsets, and partitioning provides logical organization to enhance query efficiency.
Data access involves multiple considerations: query interfaces such as SQL and programmatic access for retrieving and manipulating data, security through role-based access control and data protection measures, performance optimization for fast query execution, and integration via APIs and connectors for seamless interaction with various tools and platforms.
Current Solutions and Their Trade-offs
Section titled “Current Solutions and Their Trade-offs”Managed Services
Section titled “Managed Services”Cloud providers offer a wide range of managed services for real-time data processing, enabling organizations to build scalable, low-latency analytics pipelines without managing underlying infrastructure.
Notable solutions include AWS Kinesis combined with Redshift Streaming Ingestion for integrated streaming data ingestion and analytics, Google Cloud Dataflow with BigQuery offering a fully serverless approach to stream processing and real-time querying, and Azure Stream Analytics with Synapse Analytics facilitating real-time analytics pipelines. Tinybird represents another commonly used managed service that simplifies creating real-time APIs from streaming data.
These services allow businesses to ingest, process, and analyze data continuously, supporting use cases ranging from operational monitoring to real-time business intelligence. However, they come with significant costs, vendor lock-in risks, and limited customization options, making them often overkill for smaller teams or simpler projects.
Open-Source Solutions
Section titled “Open-Source Solutions”The open-source ecosystem offers powerful tools for building custom real-time data platforms. Apache Kafka remains the de facto standard for distributed data streaming and ingestion (Saravanan et al., 2023, p. 89457), while Apache Flink provides a robust framework for complex stream processing and real-time analytics. For analytics-focused storage, ClickHouse offers high-performance, column-oriented database optimization for analytical queries. Apache Druid delivers sub-second query performance for real-time dashboards, and Apache Pinot excels at low-latency analytics on high-throughput event streams.
However, these tools require significant expertise to deploy and operate effectively (Bellemare, 2020, p. 34). Teams need deep understanding of distributed system architecture, performance tuning, monitoring and observability, security and access control, and infrastructure management to ensure reliable operation at scale.
The Integration Challenge
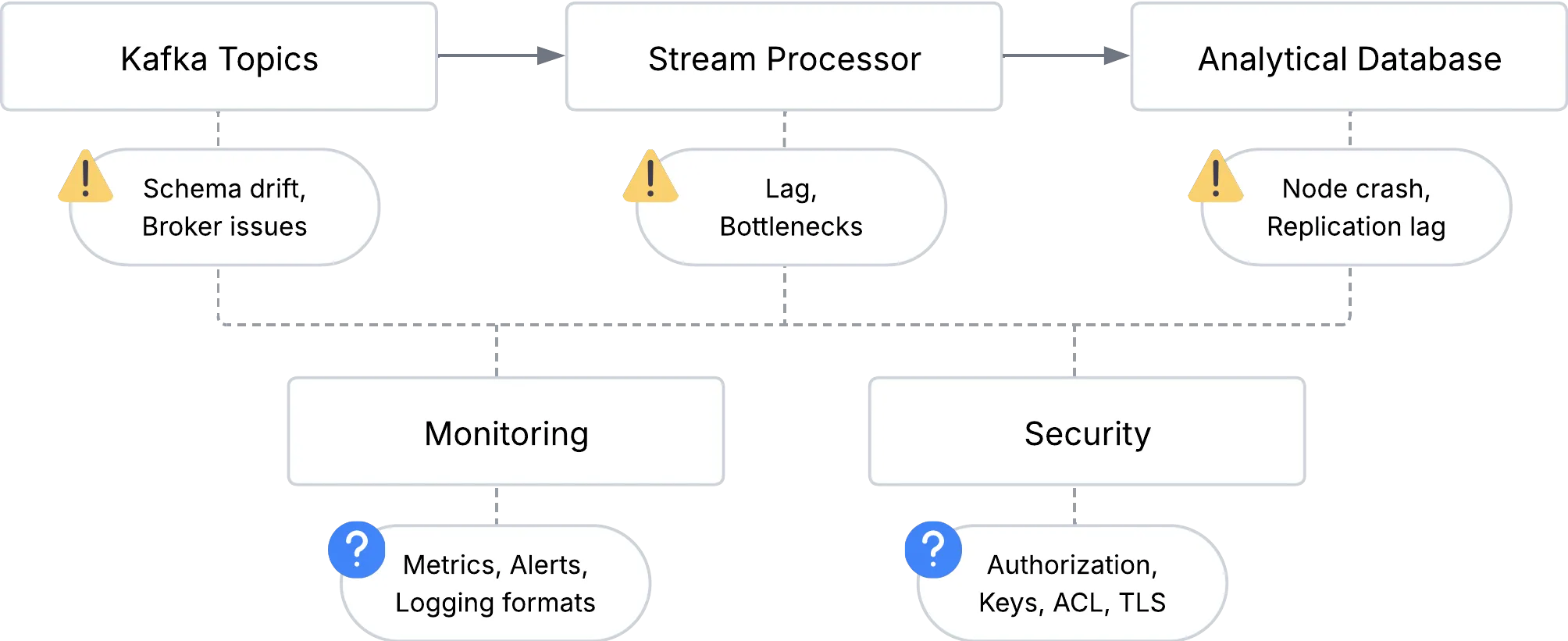
Section titled “The Integration Challenge”Even with the right individual components, integrating them into a cohesive platform presents significant challenges that often catch teams off guard. Data must flow seamlessly between Kafka topics, stream processors, and analytical databases, but each handoff introduces potential points of failure where events can be lost, duplicated, or arrive out of order (Akidau et al., 2018, p. 234). Schema changes in upstream systems can break downstream consumers, creating cascading failures across the entire pipeline.
When failures occur (and they inevitably do in distributed systems) the complexity multiplies. A ClickHouse node going down during peak load, a Kafka consumer falling behind due to processing bottlenecks, or a network partition splitting the cluster all require different recovery strategies. Meanwhile, monitoring such a distributed system means tracking metrics across multiple technologies, each with its own logging formats, alerting mechanisms, and performance characteristics.
Security adds another layer of complexity, as teams must implement authentication and authorization consistently across Kafka brokers, database connections, and API endpoints, often with different security models and configuration approaches for each component.
The Skills Gap
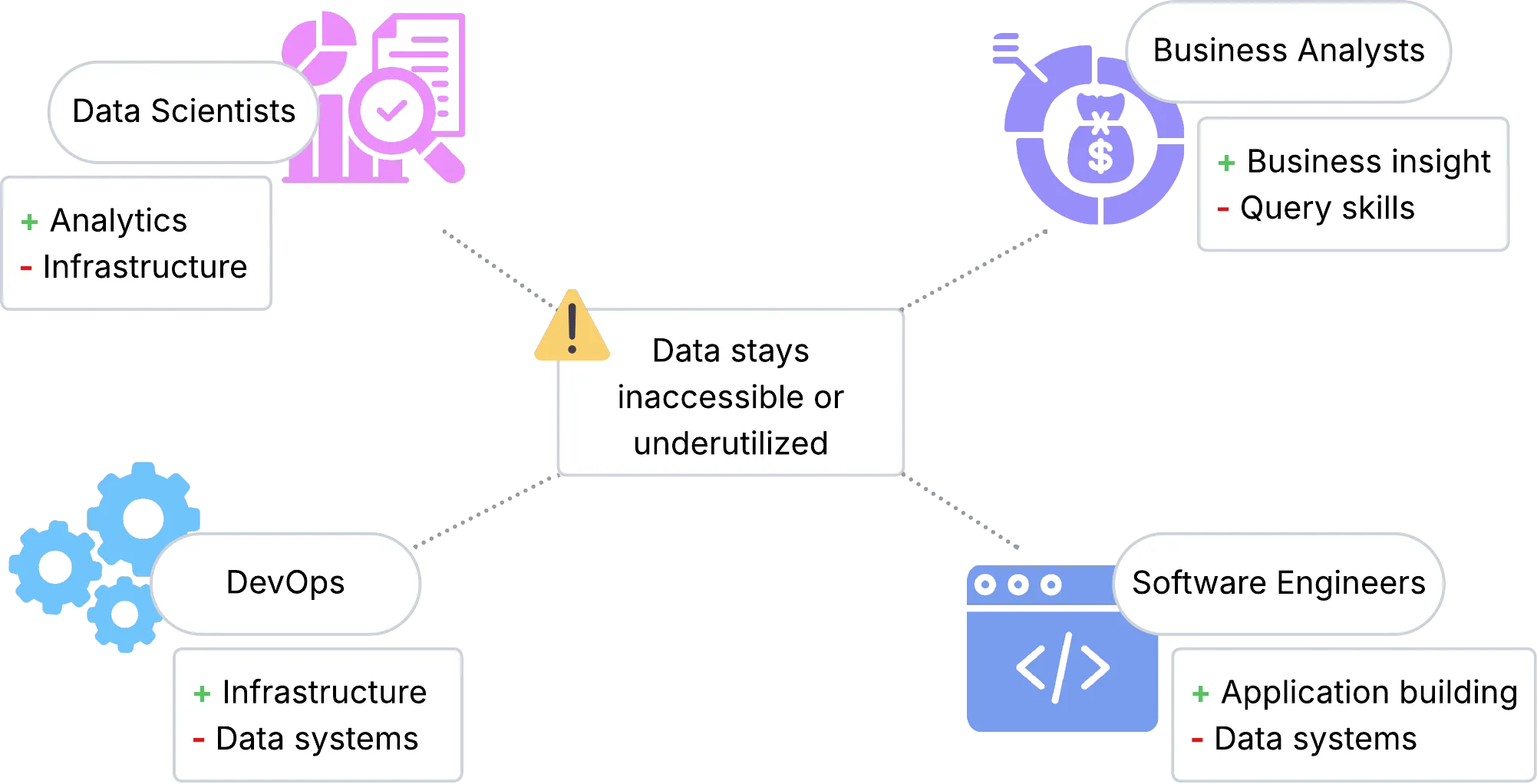
Section titled “The Skills Gap”The complexity of real-time data platforms has created a significant skills gap in the industry (Kleppmann, 2017, p. 15). Many organizations have data scientists who understand analytics but lack infrastructure expertise, software engineers who can build applications but aren’t familiar with data engineering, DevOps engineers who manage infrastructure but don’t specialize in data systems, and business analysts who need data insights but can’t write complex queries.
This skills gap means that valuable data often remains inaccessible or underutilized, limiting the organization’s ability to make data-driven decisions.
The Cost of Complexity
Section titled “The Cost of Complexity”The complexity of real-time data platforms often results in significant business costs. Development time for building and configuring infrastructure often takes months, diverting teams from delivering direct business value (Bellemare, 2020, p. 67). Once deployed, these platforms incur ongoing operational overhead as maintenance and troubleshooting continuously consume valuable engineering resources.
Data latency compounds the issue, as delays in data availability diminish the usefulness of insights for decision-making. Complex interfaces can hinder user adoption, preventing business users from accessing data independently and efficiently. These factors contribute to a high total cost of ownership, driven by both infrastructure expenses and the personnel required to sustain such intricate systems.

The Opportunity
Section titled “The Opportunity”This challenging landscape presents a significant opportunity: building an open-source platform that makes real-time data accessible without requiring deep expertise in distributed systems, stream processing, or database optimization.
Such a platform would simplify and broaden data access, enabling business users to explore data independently. It would reduce time to value by allowing teams to gain insights from data in minutes rather than months, while lowering total cost through reduced infrastructure and personnel requirements (Kreps, 2014, p. 78). Additionally, it would increase organizational agility, allowing teams to respond quickly to changing business needs, and improve data quality through centralized management with built-in quality controls.
Aurora was built to address this opportunity by providing a unified platform that abstracts away the complexity of real-time data infrastructure while maintaining the performance and reliability required for production use.